1. 线性回归
1.1. 目标函数与损失函数
$$\hat y = \theta_0+\theta_1x_1+…+\theta_nx_n$$
写成向量化的形式为:
$$h_{\theta}=\theta^TX$$
优化目标为最小化均方差 (MSE):
$$\min_{\theta} MSE(\theta)=\frac 12 \sum_{i=1}^m (\theta^TX^{(i)}-y^{(i)})^2$$
1.2. 标准方程求解
用标准方程法得到线性回归问题的闭式解,表达式为
$$\theta^*=(X^TX)^{-1}X^Ty$$
可以使用Numpy中的线性代数模块 np.linalg 进行求解
1 | import numpy as np |
也可以用Scikit-Learn实现
1 | from sklearn.linear_model import LinearRegression |
1.3. 梯度下降求解
应用梯度下降时,需要保证所有特征值的大小比例差不多(比如使用Scikit-Learn的StandardScaler类),否则收敛时间会长很多
批量梯度下降 (Batch Gradient Descent, BGD)
成本函数的偏导数
$$\frac{\partial}{\partial \theta_j} MSE(\theta)=\frac{2}{m}\sum_{i=1}^m (\theta^TX^{(i)}-y^{(i)})X_j^{(i)}$$
向量化表示为
$$\nabla_{\theta}MSE(\theta)=\frac 2m X^T(X\theta-y)$$
则每一步迭代后得到新的$\theta$为
$$\theta = \theta - \eta \nabla_{\theta}MSE(\theta)$$
我们来看看这个算法的快速实现:
1
2
3
4
5
6
7
8
9
10
11
12import numpy as np
eta = 0.1 # 学习率
n_iterations = 1000
m = 100
# 随机初始化
theta = np.random.rand(2,1)
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta)-y)
theta = theta - eta * gradients随机梯度下降 (Stochastic Gradient Descent, SGD)
批量梯度下降的主要问题是每一次迭代要用到整个训练集,所以如果训练集很大的话,算法会很慢
随机梯度下降是另外一个极端:每一步迭代只从训练集中随机选择一个样本,并且仅依据这一个样本来计算梯度,由于它的随机性,使得它与梯度下降相比要不规则得多,存在比较明显的震荡,但从整体上来看,还是在慢慢下降的
当成本函数不规则时,随机梯度下降其实可以帮助算法跳出局部最优,所以相比梯度下降,它对找到全局最优更有优势
随机性的好处在于可以逃离局部最优,但缺点是永远定位不出最优解,如果要解决这个问题,有一个办法是逐步降低学习率:开始的步长比较大(这有助于快速进展和逃离局部最优),然后越来越小,让算法尽量靠近全局最小值——这个过程叫作模拟退火
确定每个迭代学习率的函数叫作学习计划 (learning schedule)
用自定义的脚本来执行SGD:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17n_epochs = 50
t0, t1 = 5, 50 # 学习计划的超参数
def learning_schedule(t):
return t0 / (t + t1)
# 随机初始化
theta = np.random.rand(2,1)
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m) # 随机选择一个样本
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2/m * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients在Scikit-Learn里,用SGD执行线性回归可以使用
SGDRegression类,其默认优化的成本函数为平方误差1
2
3
4from sklearn.linear_model import SGDRegression
sgd_reg = SGDRegression(n_iter=50, penalty=None, eta0=o.1)
sgd_reg.fit(X, y.ravel())小批量梯度下降 (Mini-Batch Gradient Descent)
优点:
- 可以从矩阵运算的硬件优化中获得显著的性能提升;
在参数空间的搜索进程不像SGD那样不稳定,所以它会比SGD跟接近最小值;
缺点:
更难从局部最小值中逃脱
2. logistic回归:“达观杯”文本智能处理挑战赛
2.1. 任务描述
具体任务可以到 ‘达观杯’文本智能处理挑战赛官网 查看
任务:建立模型通过长文本数据正文(article),预测文本对应的类别(class)
数据:
数据包含2个csv文件:
train_set.csv
此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
test_set.csv
此数据用于测试。数据格式同train_set.csv,但不包含class
注:test_set与train_test中文章id的编号是独立的。
2.2. 编程实现
使用logistic回归来实现这个多元分类任务
1 | import pandas as pd |
2.3. sklearn包中logistic算法的使用







3. 决策树:鸢尾花数据分类
3.1. DecisionTreeClassifier实例
1 | from itertools import product |
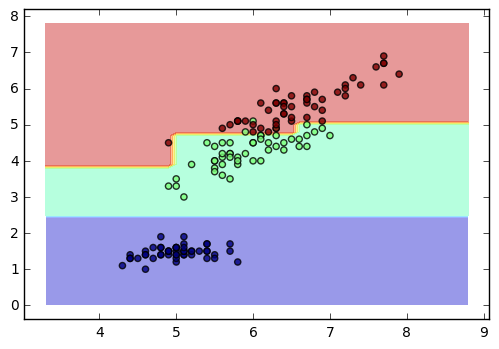
3.2. 可视化决策树
scikit-learn中决策树的可视化一般需要安装graphviz,主要包括graphviz的安装和python的graphviz插件的安装
1) 安装graphviz。下载地址在:
http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH2) 安装python插件graphviz:
pip install graphviz
- 3) 安装python插件pydotplus:
pip install pydotplus
这样环境就搭好了,有时候python会很笨,仍然找不到graphviz,这时,可以在代码里面加入这一行:
1 | os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' |
可视化决策树的代码:
1 | from IPython.display import Image |

4. SVM:sklearn中测试数据
4.1. SVM相关知识点回顾
4.1.1. SVM与SVR
SVM分类算法
其原始形式是:
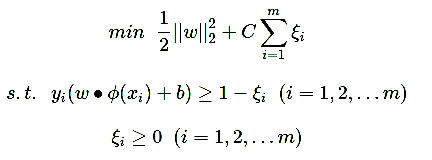
其中m为样本个数,我们的样本为(x1,y1),(x2,y2),…,(xm,ym)。w,b是我们的分离超平面的w∙ϕ(xi)+b=0系数, ξi为第i个样本的松弛系数, C为惩罚系数。ϕ(xi)为低维到高维的映射函数
通过拉格朗日函数以及对偶化后的形式为:

SVR回归算法

其中m为样本个数,我们的样本为(x1,y1),(x2,y2),…,(xm,ym)。w,b是我们的回归超平面的w∙xi+b=0系数, ξ∨i,ξ∧i为第i个样本的松弛系数, C为惩罚系数,ϵ为损失边界,到超平面距离小于ϵ的训练集的点没有损失。ϕ(xi)为低维到高维的映射函数。
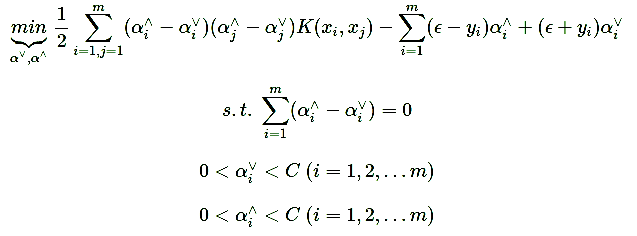
4.1.2. 核函数
在scikit-learn中,内置的核函数一共有4种:
线性核函数(Linear Kernel)表达式为:K(x,z)=x∙z,就是普通的内积
多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为:K(x,z)=(γx∙z+r)d ,其中,γ,r,d都需要自己调参定义
高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是 libsvm 默认的核函数,当然也是 scikit-learn 默认的核函数。表达式为:K(x,z)=exp(−γ||x−z||2), 其中,γ大于0,需要自己调参定义
Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为:K(x,z)=tanh(γx∙z+r), 其中,γ,r都需要自己调参定义
一般情况下,对非线性数据使用默认的高斯核函数会有比较好的效果,如果你不是SVM调参高手的话,建议使用高斯核来做数据分析。
4.2. sklearn中SVM相关库的简介
scikit-learn SVM算法库封装了libsvm 和 liblinear 的实现,仅仅重写了算法了接口部分
4.2.1. 分类库与回归库
分类算法库
包括SVC, NuSVC,和LinearSVC 3个类
对于SVC, NuSVC,和LinearSVC 3个分类的类,SVC和 NuSVC差不多,区别仅仅在于对损失的度量方式不同,而LinearSVC从名字就可以看出,他是线性分类,也就是不支持各种低维到高维的核函数,仅仅支持线性核函数,对线性不可分的数据不能使用
回归算法库
包括SVR, NuSVR,和LinearSVR 3个类
同样的,对于SVR, NuSVR,和LinearSVR 3个回归的类, SVR和NuSVR差不多,区别也仅仅在于对损失的度量方式不同。LinearSVR是线性回归,只能使用线性核函数
4.2.2. 高斯核调参
4.2.2.1. 需要调节的参数
SVM分类模型
如果是SVM分类模型,这两个超参数分别是惩罚系数C和RBF核函数的系数γ
惩罚系数C
它在优化函数里主要是平衡支持向量的复杂度和误分类率这两者之间的关系,可以理解为正则化系数
当C比较大时,我们的损失函数也会越大,这意味着我们不愿意放弃比较远的离群点。这样我们会有更加多的支持向量,也就是说支持向量和超平面的模型也会变得越复杂,也容易过拟合
当C比较小时,意味我们不想理那些离群点,会选择较少的样本来做支持向量,最终的支持向量和超平面的模型也会简单
scikit-learn中默认值是1
C越大,泛化能力越差,易出现过拟合现象;C越小,泛化能力越好,易出现过欠拟合现象
BF核函数的参数γ
RBF 核函数K(x,z)=exp(−γ||x−z||2) γ>0
γ主要定义了单个样本对整个分类超平面的影响
当γ比较小时,单个样本对整个分类超平面的影响比较小,不容易被选择为支持向量
当γ比较大时,单个样本对整个分类超平面的影响比较大,更容易被选择为支持向量,或者说整个模型的支持向量也会多
scikit-learn中默认值是
1/样本特征数γ越大,训练集拟合越好,泛化能力越差,易出现过拟合现象
如果把惩罚系数C和RBF核函数的系数γ一起看,当C比较大, γ比较大时,我们会有更多的支持向量,我们的模型会比较复杂,容易过拟合一些。如果C比较小 , γ比较小时,模型会变得简单,支持向量的个数会少
SVM回归模型
SVM回归模型的RBF核比分类模型要复杂一点,因为此时我们除了惩罚系数C和RBF核函数的系数γ之外,还多了一个损失距离度量ϵ
对于损失距离度量ϵ,它决定了样本点到超平面的距离损失
当 ϵ 比较大时,损失较小,更多的点在损失距离范围之内,而没有损失,模型较简单
当 ϵ 比较小时,损失函数会较大,模型也会变得复杂
scikit-learn中默认值是0.1
如果把惩罚系数C,RBF核函数的系数γ和损失距离度量ϵ一起看,当C比较大, γ比较大,ϵ比较小时,我们会有更多的支持向量,我们的模型会比较复杂,容易过拟合一些。如果C比较小 , γ比较小,ϵ比较大时,模型会变得简单,支持向量的个数会少
4.2.2.2. 调参方法:网格搜索
对于SVM的RBF核,我们主要的调参方法都是交叉验证。具体在scikit-learn中,主要是使用网格搜索,即GridSearchCV类
1 | from sklearn.model_selection import GridSearchCV |
将GridSearchCV类用于SVM RBF调参时要注意的参数有:
1) estimator:即我们的模型,此处我们就是带高斯核的SVC或者SVR
2) param_grid:即我们要调参的参数列表。 比如我们用SVC分类模型的话,那么param_grid可以定义为{“C”:[0.1, 1, 10], “gamma”: [0.1, 0.2, 0.3]},这样我们就会有9种超参数的组合来进行网格搜索,选择一个拟合分数最好的超平面系数
3) cv:S折交叉验证的折数,即将训练集分成多少份来进行交叉验证。默认是3。如果样本较多的话,可以适度增大cv的值
4.3. 编程实现
生成测试数据
1
2
3
4
5
6from sklearn.datasets import make_circles
from sklearn.preprocessing import StandardScaler
# 生成一些随机数据用于后续分类
X, y = make_circles(noise=0.2, factor=0.5, random_state=1) # 生成时加入了一些噪声
X = StandardScaler().fit_transform(X) # 把数据归一化生成的随机数据可视化结果如下:

调参
接着采用网格搜索的策略进行RBF核函数参数搜索
1
2
3
4
5
6
7
8from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(SVC(), param_grid={"C":[0.1, 1, 10], "gamma": [1, 0.1, 0.01]}, cv=4) # 总共有9种参数组合的搜索空间
grid.fit(X, y)
print("The best parameters are %s with a score of %0.2f"
% (grid.best_params_, grid.best_score_))
输出为:
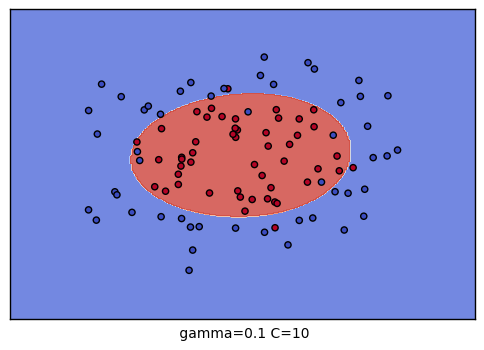
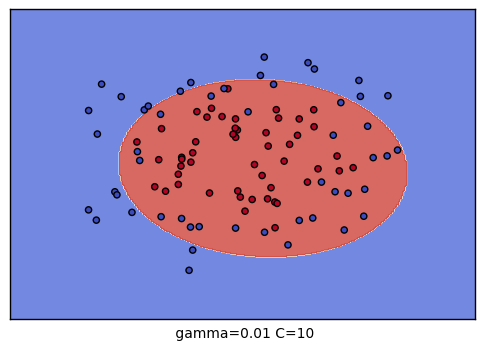
The best parameters are {'C': 10, 'gamma': 0.1} with a score of 0.91可以对9种参数组合训练的结果进行可视化,观察分类的效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max,0.02),
np.arange(y_min, y_max, 0.02))
for i, C in enumerate((0.1, 1, 10)):
for j, gamma in enumerate((1, 0.1, 0.01)):
plt.subplot()
clf = SVC(C=C, gamma=gamma)
clf.fit(X,y)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.xlabel(" gamma=" + str(gamma) + " C=" + str(C))
plt.show()
C \ gamma |
1 | 0.1 | 0.001 |
|---|---|---|---|
| 0.1 |  |
 |
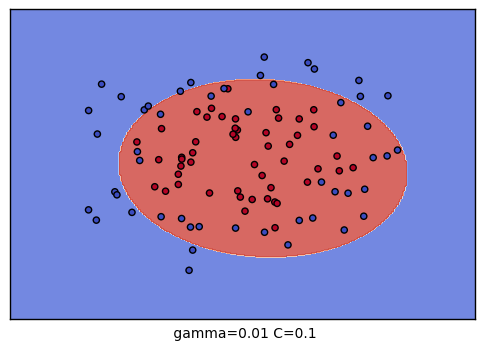 |
| 1 | 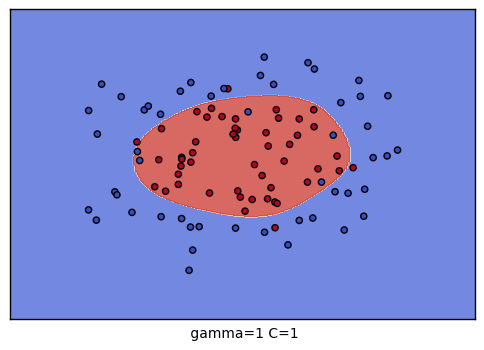 |
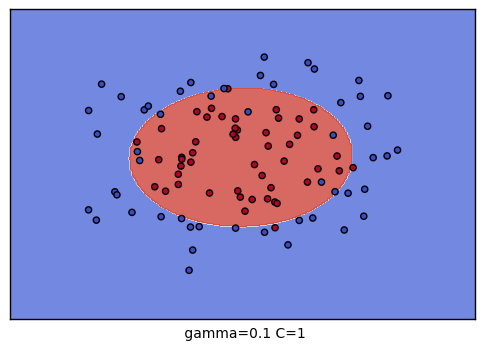 |
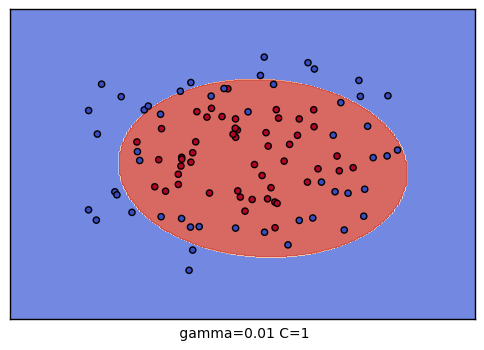 |
| 10 | 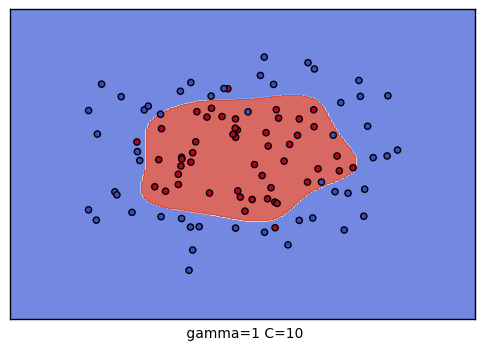 |
 |
 |
5.朴素贝叶斯
5.1. 朴素贝叶斯相关知识点回顾
5.1.1. 什么是朴素贝叶斯分类器
判别式模型(discriminative models):像决策树、BP神经网络、支持向量机等,都可以归入判别式模型,它们都是直接学习出输出Y与特征X的关系,如:
- 决策函数 Y=f(X)
- 条件概率 P(Y|X)
生成式模型 (gernerative models):先对联合概率分布 P(X,Y) 进行建模,然后再由此获得P(Y|X) = P(X,Y)/P(X)
贝叶斯学派的思想:
贝叶斯学派的思想可以概括为先验概率+数据=后验概率。也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。数据大家好理解,被频率学派攻击的是先验概率,一般来说先验概率就是我们对于数据所在领域的历史经验,但是这个经验常常难以量化或者模型化,于是贝叶斯学派大胆的假设先验分布的模型,比如正态分布,beta分布等。这个假设一般没有特定的依据,因此一直被频率学派认为很荒谬。虽然难以从严密的数学逻辑里推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论很好用,比如垃圾邮件分类,文本分类
如何对P(X,Y)进行建模?
假如我们的分类模型样本是:
(x(1)1,x(1)2,…x(1)n,y1), (x(2)1,x(2)2,…x(2)n,y2),…(x(m)1,x(m)2, …, x(m)n,ym)
则
P(X, Y) = P(Y) * P( X = (x1, x2, …, xn) | Y )
其中
P( X = (x1, x2, …, xn) | Y ) = P( x1 | Y) * P( x2 | Y, x1) * … P( xn | Y, x1, … , xn-1)
这是一个超级复杂的有n个维度的条件分布,很难求出
朴素贝叶斯模型在这里做了一个大胆的假设,即X的n个维度之间相互独立,这样就可以得出:
P( X = (x1, x2, …, xn) | Y ) = P( x1 | Y) * P( x2 | Y) * … * P( xn | Y)
5.1.2. 朴素贝叶斯推断

5.1.3. 朴素贝叶斯学习
需要从训练样本中学习到以下两个参数:
先验概率 P(c)
P(c)表示了样本空间中各类样本所占的比例
根据大数定律,当训练集中包含充足的独立同分布样本时,P(c)可根据各类样本出现的频率来估计
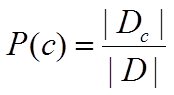
类条件概率(又称为似然) P(xi | c)
(1)如果 xi 是离散的,可以假设 xi符合多项式分布,这样得到 P(xi | c) 是在样本类别 c 中,特征 xi 出现的频率
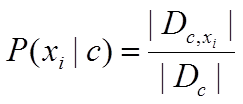
(2)如果 xi 是连续属性,可以假设 P(xi | c) ~ N( μc,i , σ2c,i )
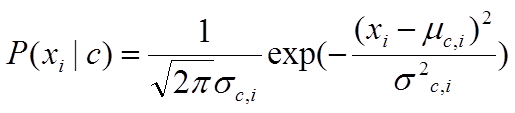
5.2. sklearn中朴素贝叶斯类库的简介
在scikit-learn中,一共有3个朴素贝叶斯的分类算法类
GaussianNB:先验为高斯分布的朴素贝叶斯
MultinomialNB:先验为多项式分布的朴素贝叶斯
BernoulliNB:先验为伯努利分布的朴素贝叶斯
这三个类适用的分类场景各不相同
一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好
如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适
如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
5.2.1. GaussianNB类
GaussianNB类的主要参数仅有一个,即先验概率priors
这个值默认不给出,如果不给出此时P(Y=c)= mc / m,如果给出的话就以priors 为准
在使用GaussianNB的fit方法拟合数据后,我们可以进行预测。此时预测有三种方法
predict方法:就是我们最常用的预测方法,直接给出测试集的预测类别输出;
predict_proba方法:给出测试集样本在各个类别上预测的概率;
predict_log_proba方法:和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化;
1 | from sklearn.naive_bayes import GaussianNB |
5.2.2. MultinomialNB类
MultinomialNB假设特征的先验概率为多项式分布,即如下式:
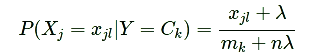
MultinomialNB参数比GaussianNB多,但是一共也只有仅仅3个
参数alpha:为上面的常数λ。如果你没有特别的需要,用默认的1即可。如果发现拟合的不好,需要调优时,可以选择稍大于1或者稍小于1的数
参数fit_prior:是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率;否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率
参数class_prior:输入先验概率,若不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率
5.2.3. BernoulliNB类
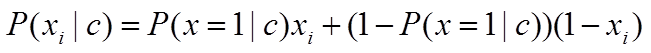
其中,x i 只能取0或1
BernoulliNB一共有4个参数,其中3个参数的名字和意义和MultinomialNB完全相同
唯一增加的一个参数是binarize,这个参数主要是用来帮BernoulliNB处理二项分布的。如果不输入,则BernoulliNB认为每个数据特征都已经是二元的。否则的话,小于binarize的会归为一类,大于binarize的会归为另外一类
6. 神经网络(sklearn):手写数字识别
5.1. 神经网络相关知识点回顾
6.1.1. 感知机:神经网络的最小单元
神经网络中最基本的成分是神经元(neuron)模型,最常见的模型是M-P神经元模型,也可以称为感知机(Perceptron)

若对生物学有一点基础的了解,就可以知道上面构造的简化的M-P神经元模型几乎完全吻合生物学上的定义:
当前神经元通过与上游神经元之间的突触结构,接受来自上游的神经元1到n传递过来的信号x1,x2…xn,由于不同的上游信号传递过来它们的影响程度是不一样的,因此对它们进行加权求和,即∑wixi,则得到总的上游信号
另外当前神经元还有一个激活阈值θ,若上游信号的汇总信号强度大于θ,即则∑wixi-θ > 0,则当前神经元被激活,处于兴奋状态;若若上游信号的汇总信号强度小于θ,即则∑wixi-θ < 0,则当前神经元未被激活,处于抑制状态
对于生物学上的神经元来说,它只有两个状态:
- “1”:对应神经元兴奋;
- “0”:对应神经元抑制;
则它接受的信号为上游神经元的输出为 xi∈{0,1},它的输出信号为 y∈{0,1}
则它的理想激活函数是阶跃函数,即f(x)=sgn(x)

然而,阶跃函数具有不连续、不光滑等不太好的性质,因此实际上常用sigmoid函数作为激活函数
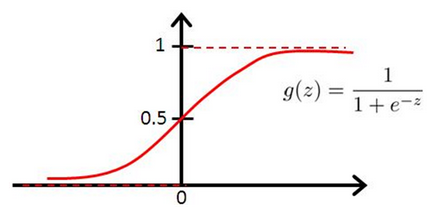
则此时激活函数为f(x)=sigmoid(∑wixi-θ),很明显若选择sigmod函数作为感知机的激活函数,则此时感知机等价于一个logistic回归分类器
类比logistic回归分类器
对于线性可分的分类任务,感知机完全等价于logistic回归分类器
对于线性不可分问题,logistic回归可以构造额外的高阶多项式:
本质上是将原始特征空间中线性不可分的样本向高维特征空间进行映射,使得它们在新的高维特征空间中线性可分
而感知器无法进行高维空间的映射,只能基于原始特征空间寻找线性判别边界,因此感知机在面对简单的非线性可分问题是,往往无法得到理想的判别面

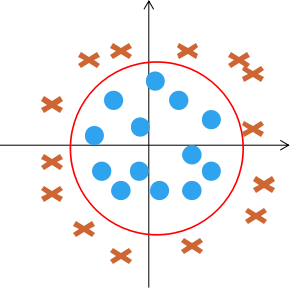
感知机的学习规则:
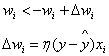
6.1.2. 神经网络的学习:BackPropagation算法
神经网络的学习算法本质上是数学上常用的梯度下降(Gradient Descend)算法
依据在一轮神经网络的训练过程中所用到的训练样本的数量的不同,可分为以下两类:
标准BP算法:每次网络训练只针对单个训练样本,一次训练就输入一个训练样本,更新一次网络参数;
累积BP算法:每次网络训练只针对所有训练样本,一次将所有训练样本输入,更新一次网络参数;
6.1.2.1. 标准BP算法
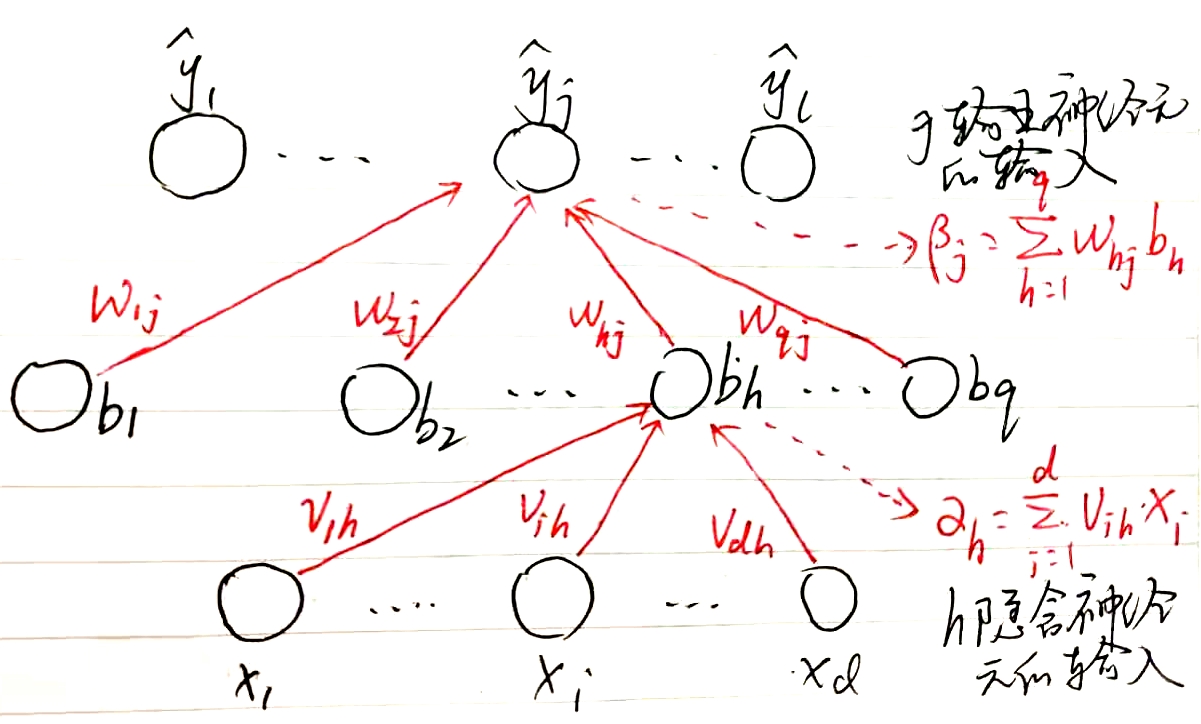
以wh,j为例进行推导
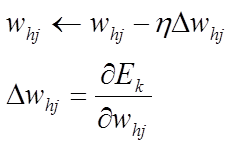
在标准BP算法中,由于只对输入的一个训练样本进行网络参数的训练,因此它的目标函数为当前样本k的均方误差Ek
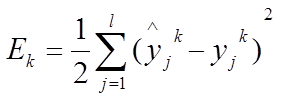
此时关键在于怎么推出△whj的表达式?
根据链式求导法则,Whj的影响链条为:
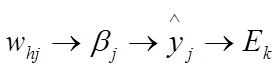
因此△whj可以写成:
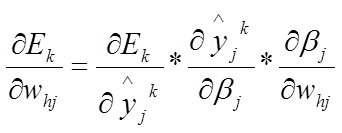
中间推导过程省略,最后得到的△whj的表达式为:

6.1.2.2. 累积BP算法
累积BP算法的目标是最小化训练集的累积误差:

这是累积BP算法与标准BP算法的最大的也是最本质的差别
标准BP算法存在的问题:
每次更新只针对单个训练样本,参数更新得非常频繁,而且不同样本训练的效果可能出现相互“抵消”的现象
因此为了达到与累积误差相同的极小点,标准BP算法往往需要进行更多次的迭代
累积BP算法的优缺点:
优点:直接对累积误差最小化,它在读取整个训练样本集D后才对参数进行一次更新,其参数更新的频率低得多
缺点:累积误差下降到一点程度之后,进一步下降会非常缓慢
此时标准BP算法往往会更快得到较好的解,因为其解的震荡性给它带来了一个好处——容易跳出局部最优
6.2. sklearn中神经网络库的简介
sklearn中神经网络的实现不适用于大规模数据应用。特别是 scikit-learn 不支持 GPU
6.2.1. MLPClassifier
神经网络又称为多层感知机(Multi-layer Perceptron,MLP)
sklearn中用MLP进行分类的类为MLPClassifier
主要参数说明:
| 参数 | 说明 |
|---|---|
| hidden_layer_sizes | tuple,length = n_layers - 2,默认值(100,)第i个元素表示第i个隐藏层中的神经元数量。 |
| activation | {‘identity’,‘logistic’,‘tanh’,‘relu’},默认’relu’ 隐藏层的激活函数:‘identity’,无操作激活,对实现线性瓶颈很有用,返回f(x)= x;‘logistic’,logistic sigmoid函数,返回f(x)= 1 /(1 + exp(-x));‘tanh’,双曲tan函数,返回f(x)= tanh(x);‘relu’,整流后的线性单位函数,返回f(x)= max(0,x) |
| slover | {‘lbfgs’,‘sgd’,‘adam’},默认’adam’。权重优化的求解器:’lbfgs’是准牛顿方法族的优化器;’sgd’指的是随机梯度下降。’adam’是指由Kingma,Diederik和Jimmy Ba提出的基于随机梯度的优化器。注意:默认解算器“adam”在相对较大的数据集(包含数千个训练样本或更多)方面在训练时间和验证分数方面都能很好地工作。但是,对于小型数据集,“lbfgs”可以更快地收敛并且表现更好。 |
| alpha | float,可选,默认为0.0001。L2惩罚(正则化项)参数。 |
| batch_size | int,optional,默认’auto’。用于随机优化器的minibatch的大小。如果slover是’lbfgs’,则分类器将不使用minibatch。设置为“auto”时,batch_size = min(200,n_samples) |
| learning_rate | {‘常数’,‘invscaling’,‘自适应’},默认’常数”。 用于权重更新。仅在solver =’sgd’时使用。’constant’是’learning_rate_init’给出的恒定学习率;’invscaling’使用’power_t’的逆缩放指数在每个时间步’t’逐渐降低学习速率learning_rate_, effective_learning_rate = learning_rate_init / pow(t,power_t);只要训练损失不断减少,“adaptive”将学习速率保持为“learning_rate_init”。每当两个连续的时期未能将训练损失减少至少tol,或者如果’early_stopping’开启则未能将验证分数增加至少tol,则将当前学习速率除以5。 |
MLPClassifier的训练使用BP算法,其使用交叉熵损失函数(Cross-Entropy loss function)
MLP的训练需要准备
Xm*n:m个训练样本的n维特征向量构成的特征矩阵
Ym:m训练样本的目标值组成的向量
1 | from sklearn.neural_network import MLPClassifier |
以上训练好的MLP模型保存在clf对象中,该对象有以下两个子变量:
clf.coefs_:模型的一系列权重矩阵
2
3
4
> >>[coef.shape for coef in clf.coefs_]
> [(2, 5), (5, 2), (2, 1)]
>
其中下标为 i 的权重矩阵表示第 i 层和第 i+1 层之间的权重
intercepts_:一系列偏置向量其中的下标为 i 的向量表示添加到第 i+1 层的偏置值
多分类任务
MLPClassifier 通过应用 Softmax 作为输出函数来支持多分类
softmax回归本质上是将原先常见的二元分类任务神经网络的输出层采用的sigmoid激活函数换成softmax回归
例如要利用神经网络进行k类的分类,则神经网络结构如下:
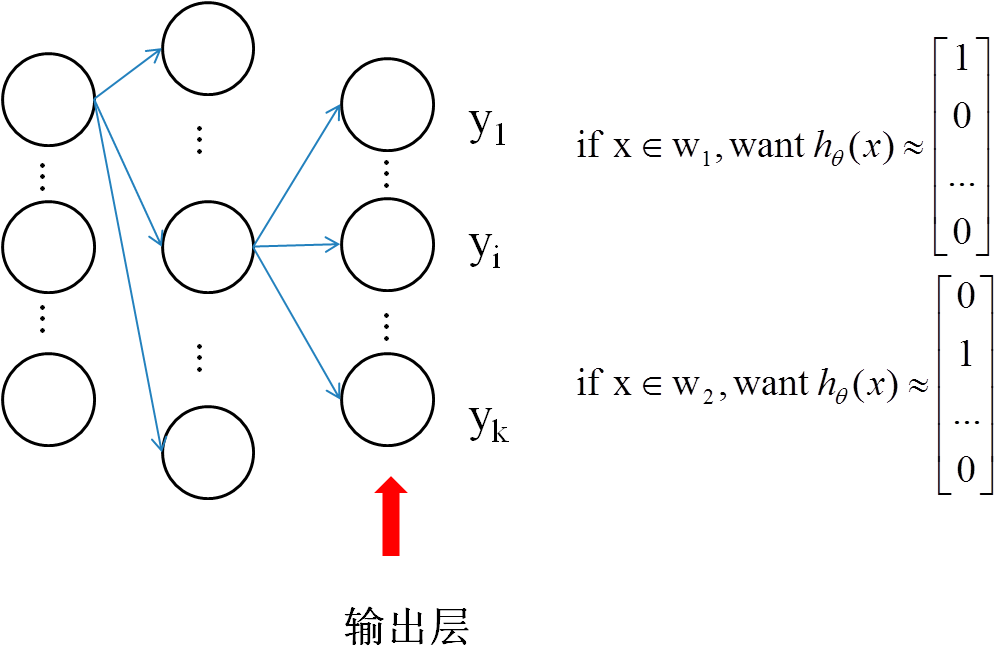
那么最后一层即网络的输出层所采用的激活函数——softmax回归到底长什么样呢?

因此该网络的输出层又被称为softmax layer
因此在提供训练集时,若总共有k的类别,当某一个训练样本的类别为第i类时,它的目标值应该为
[0, 0, ..., 1, ..., 0],只在向量的第i个位置标为1,其他位置都为0多标签分类任务
一个样本可能属于多个类别。 对于每个类,原始输出经过 logistic 函数变换后,大于或等于 0.5 的值将进为 1,否则为 0。 对于样本的预测输出,值为 1 的索引位置表示该样本的分类类别
1
2
3
4
5
6
7
8
9
10
11>>> X = [[0., 0.], [1., 1.]]
>>> y = [[0, 1], [1, 1]]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(15,), random_state=1)
...
>>> clf.fit(X, y)
>>> clf.predict([[1., 2.]])
array([[1, 1]])
>>> clf.predict([[0., 0.]])
array([[0, 1]])
6.3. 编程实现
对于神经网络,要说它的Hello world,莫过于识别手写数字了
首先要获取实验数据,下载地址:http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz
数组中的每一行都表示一个灰度图像。每个元素都表示像素所对应的灰度值。
数据集中将数据分成3类:训练集,验证集,测试集。一般情况下会将训练数据分为训练集和测试集
为什么要将训练数据分为训练集和测试集?
将原始数据分开,保证用于测试的数据是训练模型时从未遇到的数据可以使测试更客观。否则就像学习教课书的知识,又只考教课书的知识,就算不理解记下了就能得高分但遇到新问题就傻眼了。
好一点的做法就是用训练集当课本给他上课,先找出把课本知识掌握好的人,再参加由新题组成的月考即测试集,若是还是得分高,那就是真懂不是死记硬背了。
但这样选出来的模型实际是还是用训练集和测试集共同得到的,再进一步,用训练集和验证集反复训练和检测,得到最好的模型,再用测试集来一局定输赢即期末考试,这样选出来的就更好了。
本实验中为了方便将训练集与验证集合并
先载入数据,并简单查看一下数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26from sklearn.neural_network import MLPClassifier
import numpy as np
import pickle
import gzip
import matplotlib.pyplot as plt
# 加载数据
with gzip.open(r"mnist.pkl.gz") as fp:
training_data, valid_data, test_data = pickle.load(fp)
X_training_data, y_training_data = training_data
X_valid_data, y_valid_data = valid_data
X_test_data, y_test_data = test_data
# 合并训练集,验证集
X_training = np.vstack((X_training_data, X_valid_data))
y_training = np.append(y_training_data, y_valid_data)
def show_data_struct():
print X_training_data.shape, y_training_data.shape
print X_valid_data.shape, y_valid_data.shape
print X_test_data.shape, y_test_data.shape
print X_training_data[0]
print y_training_data[0]
show_data_struct()随便看几张训练图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14def show_image():
plt.figure(1)
for i in range(10):
image = X_training[i] # 得到包含第i张图的像素向量,为1*768
pixels = image.reshape((28, 28)) # 将原始像素向量转换为28*28的像素矩阵
plt.subplot(5,2,i+1)
plt.imshow(pixels, cmap='gray')
plt.title(y_training[i])
plt.axis('off')
plt.subplots_adjust(top=0.92, bottom=0.08, left=0.10, right=0.95, hspace=0.45,
wspace=0.85)
plt.show()
show_image()
训练模型
为了获得比默认参数更佳的模型,我们采用网格搜索法搜索更优的训练超参数,使用gridSearchCV实现,上文4.2.2.2. 调参方法:网格搜索中有较为详细的说明
1
2
3
4
5
6
7
8
9
10from sklearn.model_selection import GridSearchCV
mlp = MLPClassifier()
mlp_clf__tuned_parameters = {"hidden_layer_sizes": [(100,), (100, 30)],
"solver": ['adam', 'sgd', 'lbfgs'],
"max_iter": [20],
"verbose": [True]
}
estimator = GridSearchCV(mlp, mlp_clf__tuned_parameters, n_jobs=6)
estimator.fit(X_training, y_training)
7. 特征选择/特征降维:sklearn包中feature_selection模块的使用
6.1. 相关知识回顾
7.1.1. 特征降维
7.1.2. 特征选择
7.1.2.1. 特征选择的一般解决思路
目标:从初始特征集合中选取一个包含所有重要信息的特征子集
可用策略:
(1)找到该领域懂业务的专家,让他们给一些建议。比如我们需要解决一个药品疗效的分类问题,那么先找到领域专家,向他们咨询哪些因素(特征)会对该药品的疗效产生影响,较大影响的和较小影响的都要。这些特征就是我们的特征的第一候选集
(2)若没有任何领域知识作为先验假设
方差筛选:最简单的方法,方差越大的特征,那么我们可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃;
遍历所有可能的子集——计算上不可行;
产生一个“候选子集”,评价出它的好坏,基于评价结果产生下一个候选子集,再对其进行评价…这个过程持续下去,直到无法再找到更好的候选子集为止——这就是我们所说的一般的特征选择问题的处理策略;
那么这就产生了两个问题:
如何根据评价结果获取下一个候选特征子集?——子集搜索
如何评价候选特征子集的好坏?——子集评价
子集搜索
(1)给定特征结合${a_1,a_2,…,a_d}$,可将每个特征看作一个候选子集,对这d个候选单特征子集进行评价,假定${a_2}$最优,将${a_2}$作为第一轮的选定子集;
(2)在上一轮的选定子集中加入一个特征,构成包含两个特征的候选子集
假定在这d-1个候选两特征子集中${a_2,a_4}$最优,且由于${a_2}$,于是将${a_2,a_4}$作为本轮的选定子集;
(3)假定在第k+1轮时,最优的候选特征子集不如上一轮的选定集,则停止生产候选子集,并将上一轮的k特征子集作为特征选择结果
以上逐渐增加相关特征的策略称为 “前向”搜索 ,与它相对于的还有 “反向”搜索 和 “双向”搜索
注意:上述策略都是贪心的,因为它们都仅考虑了使本轮选定集最优
子集评价
给定数据集D,假定D中第i类样本所占的比例为$p_i(i=1,2,…,|y|)$,为了后面方便进行讨论,假定样本属性均为离散型
对于属性子集A,假定根据其取值将D分成V个子集${D^1,D^2,…,D^V}$,每个子集中的样本在A上取值相同
属性子集A的信息增益:
$$Gain(A)=Ent(D)-\sum_{v=1}^{V}\frac{|D^v|}{|D|}Ent(D^v)$$
其中信息熵定义为:
$$Ent(D)=-\sum_{k=1}^{|y|}p_klog_2p_k$$
信息熵增益越大,意味着特征子集A包含的有助于分类的信息越多
7.1.2.2. 具体的几种特征选择类型
特征选择方法有很多,一般分为三类:
过滤式选择
过滤式选择:先对数据集进行特征选择,它按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征然后再训练学习器——特征选择过程与后续学习器无关
相当于:先用特征选择过程对初始特征进行“过滤”,再用过滤后的特征来训练模型
方差筛选就是过滤法的一种
一个经典的过滤式特征选择方法为Relief(Relevant Features)方法:
该方法设计了一个“相关性统计量”来度量特征的重要性,该统计量是一个向量,其每一个分量对于一个初始特征,而特征子集的重要性则由子集中每个特征所对应的相关统计量之和来决定
Relief的关键是如何确定相关统计量的:
给定训练集${(x_1,y_1),(x_2,y_2),…,(x_m,y_m)}$,对每个示例$x_i$,Relief先在$x_i$的同类样本中寻找其最近邻$x_{i,nh}$,称为“猜中近邻”(near-hit),再从$x_i$的异类样本中寻找其最近邻$x_{i,nm}$,称为“猜错近邻”(near-miss)
相关统计量对应于属性j的分量为:
$$\delta^j=\sum_i[-diff(x_i^j,x_{i,nh}^j)^2+diff(x_i^j,x_{i,nm}^j)^2]$$
其中$diff(x_a^j,x_b^j)$的取值取决于属性j的类型:
- 离散型:$x_a^j=x_b^j$时,$diff(x_a^j,x_b^j)=0$,否则为1;
- 连续型:$diff(x_a^j,x_b^j)=|x_a^j-x_b^j|$
理解Relief相关统计量的意义:
若$x_i$与其猜中近邻$x_{i,nh}$在属性j上的距离小于$x_i$与其猜错近邻$x_{i,nm}$的距离,则说明该属性对于区分同类样本与异类样本是有益的,于是增大j的统计量;
反之,说明属性j起负面作用,生与死减小j对于的统计量
以上说的是Relief对于二分类问题的情况,其扩展变体Relief-F能处理多分类问题,由于篇幅有限,此处略去
其实不同过滤式选择方法主要的差别在于“相关统计量”的选择,其他常用的统计量和它们的适用场景:
相关系数:主要用于输出连续值的监督学习算法中。分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征;
假设检验:比如卡方检验。卡方检验可以检验某个特征分布和输出值分布之间的相关性,它比粗暴的方差法好用。
在sklearn中,使用chi2这个类来做卡方检验得到所有特征的卡方值与显著性水平P临界值,我们可以给定卡方值阈值, 选择卡方值较大的部分特征。
除了卡方检验,我们还可以使用F检验和t检验,它们都是使用假设检验的方法,只是使用的统计分布不是卡方分布,而是F分布和t分布而已。在sklearn中,有F检验的函数
f_classif和f_regression,分别在分类和回归特征选择时使用。互信息:从信息熵的角度分析各个特征和输出值之间的关系评分
互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。在sklearn中,可以使用
mutual_info_classif(分类)和mutual_info_regression(回归)来计算各个输入特征和输出值之间的互信息。
包裹式选择
包裹式选择:直接把最终将要使用的学习器的性能作为特征子集的评价准则
即,为给定的学习器选择最有利于其性能、“量身定做”的特征子集
其特点:
- 由于包裹式特征选择方法直接针对给定学习器进行优化,因此从最终性能来看,它比过滤式特征选择要好;
- 特征选择过程中需多次训练学习器,因此其计算开销通常比过滤式大得多;
最常用的包装法是递归消除特征法(recursive feature elimination,以下简称RFE)。递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数的对应的特征,再基于新的特征集进行下一轮训练。在sklearn中,可以使用RFE函数来选择特征。
以经典的SVM-RFE算法来讨论这个特征选择的思路:
这个算法以支持向量机来做RFE的机器学习模型选择特征
它在第一轮训练的时候,会选择所有的特征来训练,得到了分类的超平面$wx+b=0$后,如果有n个特征,那么RFE-SVM会选择出$w$中分量的平方值$w^2_i$最小的那个序号i对应的特征,将其排除
在第二轮的时候,特征数就剩下n-1个了,我们继续用这n-1个特征和输出值来训练SVM,同样的,去掉$w^2_i$最小的那个序号i对应的特征。以此类推,直到剩下的特征数满足我们的需求为止。
嵌入式选择——基于$L_1$正则化
嵌入式特征选择:将特征选择与学习器训练过程融合为一体,两者在同一个优化过程中完成,即在学习训练过程中自动地进行了特征选择
对于简单的线性回归问题,它的优化目标一般为最小化平方误差:
$$\min_\omega \, \sum_{i=1}^m(y_i-\omega^Tx_i)$$
当样本特征多而样本数又相对较少时,很容易陷入过拟合,为了缓解过拟合,需要对上面的优化目标引入最终项
若使用L2范数正则化则有
$$\min_\omega \, \sum_{i=1}^m(y_i-\omega^Tx_i)-\lambda||\omega||_2^2\quad(岭回归)$$
若使用L1范数则有
$$\min_\omega \, \sum_{i=1}^m(y_i-\omega^Tx_i)-\lambda||\omega||_1\quad(LASSO)$$
L1和L2范数都能降低过拟合的风险,而L1范数还会带来一个额外的好处:跟容易获得“稀疏”(sparse)解,即它求得的$\omega$会有更少的非零分量
7.1.3. 构造高级特征
在我们拿到已有的特征后,我们还可以根据需要寻找到更多的高级特征
比如有车的路程特征和时间间隔特征,我们就可以得到车的平均速度这个二级特征。根据车的速度特征,我们就可以得到车的加速度这个三级特征,根据车的加速度特征,我们就可以得到车的加加速度这个四级特征……也就是说,高级特征可以一直寻找下去
在Kaggle之类的算法竞赛中,高分团队主要使用的方法除了集成学习算法,剩下的主要就是在高级特征上面做文章。所以寻找高级特征是模型优化的必要步骤之一
寻找高级特征最常用的方法有:
若干项特征加和: 我们假设你希望根据每日销售额得到一周销售额的特征。你可以将最近的7天的销售额相加得到
若干项特征之差: 假设你已经拥有每周销售额以及每月销售额两项特征,可以求一周前一月内的销售额
若干项特征乘积: 假设你有商品价格和商品销量的特征,那么就可以得到销售额的特征
若干项特征除商: 假设你有每个用户的销售额和购买的商品件数,那么就是得到该用户平均每件商品的销售额
寻找高级特征的方法远不止于此,它需要你根据你的业务和模型需要而得,而不是随便的两两组合形成高级特征,这样容易导致特征爆炸,反而没有办法得到较好的模型
7.2. 功能实现
在 sklearn.feature_selection 模块中的类可以用来对样本集进行 feature selection(特征选择)和 dimensionality reduction(降维)
7.2.1. 特征降维
7.2.2. 特征选择
7.2.2.1. 移除低方差特征
VarianceThreshold 是特征选择的一个简单基本方法,它会移除所有那些方差不满足一些阈值的特征。默认情况下,它将会移除所有的零方差特征,即那些在所有的样本上的取值均不变的特征。
例如,假设我们有一个特征是布尔值的数据集,我们想要移除那些在整个数据集中特征值为0或者为1的比例超过80%的特征。布尔特征是伯努利( Bernoulli )随机变量,变量的方差为
$$Var[X] = p(1 - p)$$
因此,我们可以使用阈值 .8 * (1 - .8) 进行选择:
1 | from sklearn.feature_selection import VarianceThreshold |
7.2.2.2. 单变量特征选择
单变量的特征选择是通过基于单变量的统计测试来选择最好的特征,因此它实际采用的特征选择策略是过滤式特征选择方法中的Relief方法
SelectKBest移除那些除了评分最高的 K 个特征之外的所有特征
SelectPercentile移除除了用户指定的最高得分百分比之外的所有特征对每个特征应用常见的单变量统计测试: 假阳性率(false positive rate) SelectFpr, 伪发现率(false discovery rate) SelectFdr , 或者族系误差(family wise error) SelectFwe 。
GenericUnivariateSelect允许使用可配置方法来进行单变量特征选择。它允许超参数搜索评估器来选择最好的单变量特征。
例如下面的实例,我们可以使用 x2 检验样本集来选择最好的两个特征:
1 | from sklearn.datasets import load_iris |
对于回归问题和分类问题,适用的统计量是不一样的:
- 对于回归:
f_regression,mutual_info_regression- 对于分类:
chi2,f_classif,mutual_info_classif
注意:不要使用一个回归评分函数来处理分类问题,你会得到无用的结果
7.2.2.3. 递归式特征消除
给定一个外部的估计器,可以对特征赋予一定的权重(比如,线性模型的相关系数),recursive feature elimination ( RFE ) 通过考虑越来越小的特征集合来递归的选择特征。
首先,评估器在初始的特征集合上面训练并且每一个特征的重要程度是通过一个 coef_ 属性 或者 feature_importances_ 属性来获得。 然后,从当前的特征集合中移除最不重要的特征。在特征集合上不断的重复递归这个步骤,直到最终达到所需要的特征数量为止。 RFECV 在一个交叉验证的循环中执行 RFE 来找到最优的特征数量
参考资料:
(1) 机械工业出版社《机器学习实战:基于Scikit-Learn和TensorFlow》
(2) 【GitHub】MLjian/TextClassificationImplement
(3) 刘建平Pinard《scikit-learn 逻辑回归类库使用小结》
(4) loveliuzz《机器学习sklearn19.0——Logistic回归算法》
(5) 刘建平Pinard《scikit-learn决策树算法类库使用小结》
(6) loveliuzz《机器学习sklearn19.0——决策树算法》
(7) 刘建平Pinard《scikit-learn 支持向量机算法库使用小结》
(9) loveliuzz《机器学习sklearn19.0——SVM算法》
(10) 周志华《机器学习:第7章 贝叶斯分类器》
(12) 刘建平Pinard《scikit-learn 朴素贝叶斯类库使用小结》
(13) 周志华《机器学习:第5章 神经网络》
(14) 吴恩达《deeplearning.ai:改善深层神经网络》
(15) scikit-learn中文网《神经网络模型(有监督)》
(16) 啊噗不是阿婆主《sklearn 神经网络MLPclassifier参数详解》
(18) 周志华《机器学习:第11章 特征选择与稀疏学习》
(19) 刘建平Pinard《特征工程之特征选择》
(20) sklearn中文文档:特征选择