1. Kaggle 基本介绍
Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台
在 Kaggle 上,企业或者研究机构发布商业和科研难题,悬赏吸引全球的数据科学家,通过众包的方式解决建模问题。而参赛者可以接触到丰富的真实数据,解决实际问题,角逐名次,赢取奖金。诸如 Google,Facebook,Microsoft 等知名科技公司均在 Kaggle 上面举办过数据挖掘比赛
2017年3月,Kaggle 被 Google CloudNext 收购
1.1. 参赛方式
可以以个人或者组队的形式参加比赛
组队人数一般没有限制,但需要在 Merger Deadline 前完成组队
关于组队,建议先单独个人进行数据探索和模型构建,以个人身份进行比赛,在比赛后期(譬如离比赛结束还有 2~3 周)再进行组队,以充分发挥组队的效果(类似于模型集成,模型差异性越大,越有可能有助于效果的提升,超越单模型的效果)
也可以一开始就组好队,方便分工协作,讨论问题和碰撞火花
Kaggle 对比赛的公正性相当重视:
(1)每个人只允许使用一个账号进行提交
在比赛结束后 1~2 周内,Kaggle 会对使用多账号提交的 Cheater 进行剔除(一般会对 Top 100 的队伍进行 Cheater Detection)。在被剔除者的 Kaggle 个人页面上,该比赛的成绩也会被删除,相当于该选手从没参加过这个比赛
(2)队伍之间也不能私自分享代码或者数据,除非在论坛上面公开发布
比赛一般只提交测试集的预测结果,无需提交代码。每人(或每个队伍)每天有提交次数的限制,一般为2次或者5次,在 Submission 页面会有提示
1.2. 比赛获奖
Kaggle 比赛奖金丰厚,一般前三名均可以获得奖金
在最近落幕的第二届 National Data Science Bowl 中,总奖金池高达 100W 美刀,其中第一名可以获得 50W 美刀的奖励,即使是第十名也能收获 2.5W 美刀的奖金
如何领奖?
获奖的队伍需要在比赛结束后 1~2 周内,准备好可执行的代码以及 README,算法说明文档等提交给 Kaggle 来进行获奖资格的审核
Kaggle 会邀请获奖队伍在 Kaggle Blog 中发表 Interview,来分享比赛故事和经验心得。对于某些比赛,Kaggle 或者主办方会邀请获奖队伍进行电话/视频会议,获奖队伍进行 Presentation,并与主办方团队进行交流
1.3. 比赛类型
!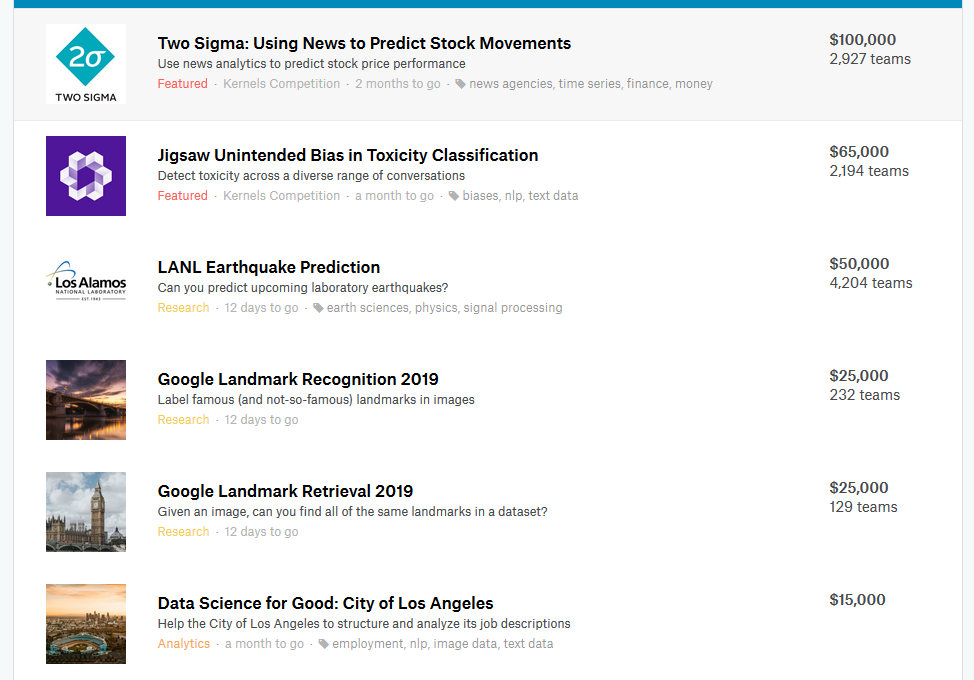
从 Kaggle 提供的官方分类来看,可以划分为以下类型:
Featured:商业或科研难题,奖金一般较为丰厚;
Recruitment:比赛的奖励为面试机会;
Research:科研和学术性较强的比赛,也会有一定的奖金,一般需要较强的领域和专业知识;
Playground:提供一些公开的数据集用于尝试模型和算法;
Getting Started:提供一些简单的任务用于熟悉平台和比赛;
In Class:用于课堂项目作业或者考试;
其他角度的分类:
从领域归属划分:包含搜索相关性,广告点击率预估,销量预估,贷款违约判定,癌症检测等
从任务目标划分:包含回归,分类(二分类,多分类,多标签),排序,混合体(分类+回归)等
从数据载体划分:包含文本,语音,图像和时序序列等
从特征形式划分:包含原始数据,明文特征,脱敏特征(特征的含义不清楚)等
1.4. 比赛流程

特别强调的一点:Kaggle 在计算得分的时候,有 Public Leaderboard (LB) 和 Private LB 之分
具体而言,参赛选手提交整个测试集的预测结果,Kaggle 使用测试集的一部分计算得分和排名,实时显示在 Public LB上,用于给选手提供及时的反馈和动态展示比赛的进行情况;测试集的剩余部分用于计算参赛选手的最终得分和排名,此即为 Private LB,在比赛结束后会揭晓
用于计算 Public LB 和 Private LB 的数据有不同的划分方式,具体视比赛和数据的类型而定,一般有随机划分,按时间划分或者按一定规则划分
划分数据集的各部分以及它们之间的关系:

划分Public Leaderboard (LB) 和 Private LB 的目的:
目的是避免模型过拟合,以得到泛化能力好的模型
如果不设置 Private LB(即所有的测试数据都用于计算 Public LB),选手不断地从 Public LB(即测试集)中获得反馈,进而调整或筛选模型。这种情况下,测试集实际上是作为验证集参与到模型的构建和调优中来
Public LB上面的效果并非是在真实未知数据上面的效果,不能可靠地反映模型的效果。划分 Public LB 和 Private LB 这样的设置,也在提醒参赛者,我们建模的目标是要获得一个在未知数据上表现良好的模型,而并非仅仅是在已知数据上效果好
2. 数据挖掘比赛基本流程
2.1. 数据分析
数据分析可能涉及以下方面:
分析特征变量的分布
特征变量为连续值:如果为长尾分布并且考虑使用线性模型,可以对变量进行幂变换或者对数变换;
特征变量为离散值:观察每个离散值的频率分布,对于频次较低的特征,可以考虑统一编码为“其他”类别;
分析目标变量的分布
目标变量为连续值:
首先,能确定这是一个回归任务
查看其值域范围是否较大,如果较大,可以考虑对其进行对数变换,并以变换后的值作为新的目标变量进行建模(在这种情况下,需要对预测结果进行逆变换)
一般情况下,可以对连续变量进行Box-Cox变换。通过变换可以使得模型更好的优化,通常也会带来效果上的提升
目标变量为离散值:
首先,能确定这是一个分类任务
如果数据分布不平衡,考虑是否需要上采样/下采样;如果目标变量在某个ID上面分布不平衡,在划分本地训练集和验证集的时候,需要考虑分层采样(Stratified Sampling)
分析变量之间两两的分布和相关度
可以用于发现高相关和共线性的特征
通过对数据进行探索性分析(甚至有些情况下需要肉眼观察样本),还可以有助于启发数据清洗和特征抽取,譬如缺失值和异常值的处理,文本数据是否需要进行拼写纠正等
2.2. 数据清洗
常用的数据清洗一般包括:
特征缺失值的处理
特征值为连续值:
按不同的分布类型对缺失值进行补全:
- 偏正态分布,使用均值代替,可以保持数据的均值;
- 偏长尾分布,使用中值代替,避免受 outlier 的影响;
特征值为离散值:使用众数代替
文本数据的清洗
在比赛当中,如果数据包含文本,往往需要进行大量的数据清洗工作。如去除HTML 标签,分词,拼写纠正, 同义词替换,去除停词,抽词干,数字和单位格式统一等
2.3. 特征工程
有一种说法是,特征决定了效果的上限,而不同模型只是以不同的方式或不同的程度来逼近这个上限
好的特征输入对于模型的效果至关重要,正所谓:Garbage in, garbage out
要做好特征工程,往往跟领域知识和对问题的理解程度有很大的关系,也跟一个人的经验相关。特征工程的做法也是Case by Case
特征变换
主要针对一些长尾分布的特征,需要进行幂变换或者对数变换,使得模型(LR或者DNN)能更好的优化。需要注意的是,Random Forest 和 GBDT 等模型对单调的函数变换不敏感。其原因在于树模型在求解分裂点的时候,只考虑排序分位点
特征编码
对于离散的类别特征,往往需要进行必要的特征转换/编码才能将其作为特征输入到模型中
补充知识
*1. 上/下采样
提到上/下采样 (upsampling or downsampling),一般想到的是图像处理任务:
在图像处理任务中,一般上采样=放大图像,下采样=缩小图像
缩小图像
主要目的是两个:
- 使得图像符合显示区域的大小;
- 生成对应图像的缩略图;
下采样的原理:
对于一幅图像尺寸为M*N,对其进行s倍的下采样,即得到(M/s)*(N/s)尺寸的分辨率图像,当然,s应该是M和N的公约数才可以,如果考虑是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点就是窗口内所有像素的均值 $P_k = (\sum X_i)/ S^2$
放大图像
主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上
上采样的原理:
图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。插值算法还包括了传统插值,基于边缘图像的插值,还有基于区域的图像插值。
其实,上/下采样并不专属于图像处理任务,在常规机器学习任务中,上/下采样是用于解决数据不平衡问题的方法
首先来讨论一个问题:为什么类别不平衡是不好的?
举一个比较极端但是又比较直观的例子:
例如有998个反例,但正例只有2个,那么学习器只需要返回一个永远将新样本预测为反例的学习器,就能达到99.8%的正确率——然而,这样的学习学习器往往没有什么价值,因为它不能预测任何正例
下面给出一个严谨一些的数学证明:
为了简化我们的讨论,我们从线性分类器的角度去分析
一般我们说的线性分类器是逻辑回归,即 $y=\sigma(w^Tx+b)$
我们可以把逻辑回归看出是对分类概率的直接拟合,所以y值可以看作是将样本分为正例的概率,一般我们会将这个概率值与一个阈值进行比较,一般这个阈值选择0.5,即当$y>0.5$时判断为正例,否则判断为反例。
我们可以把这种决策方式写成:
$$\begin{cases} +1,\quad if \,y >0.5 \\ -1,\quad if \,y \le 0.5 \end{cases}$$
但是,你有思考过为什么大家一般都将这个阈值设为0.5吗?设为0.5总是最好的吗?
之所以设为0.5是基于训练样本中两组样本平衡的前提假设的
令$m^+$为正例样本数,令$m^-$为反例样本数,我们通常会假设训练集是真实样本总体的无偏采样,因此正例样本的观测几率为$\frac {m^+}{m^++m^-}$,即我从真实样本总体随机抽一个样本,它是正例的概率为$\frac {m^+}{m^++m^-}$,则我们只需要将y值和它的观测几率进行比较即可:
若$y > \frac {m^+}{m^++m^-}$,则说明我判断该样本预测几率是高于随机猜的概率的,我有比较大的把握把这个样本归为正例,反之,则归为反例
所以,实际的决策方式应该为:
$$\begin{cases} +1,\quad if \,y > \frac {m^+}{m^++m^-} \\ -1,\quad if \,y \le \frac {m^+}{m^++m^-}\end{cases}$$
在两类样本平衡时,$\frac {m^+}{m^++m^-}=0.5$
这就是为什么我们一般设置阈值为0.5
所以当样本不平衡时,将阈值设为0.5不对的,会带来一定的预测结果的偏差
什么是上/下采样?
(1)下采样:对于一个不均衡的数据,让目标值(如0和1分类)中的样本数据量相同,且以数据量少的一方的样本数量为准,最一般的做法是获取数据时从分类样本多的数据从随机抽取等数量的样本,但是这样做可能丢失一些重要的信息;
(2)上采样:以数据量多的一方的样本数量为标准,把样本数量较少的类的样本数量生成和样本数量多的一方相同。那么上采样能否采用和下采样相同的策略,对初始样本集合中进行随机重复采样呢?答案是,不能,这样做会导致严重的过拟合;
上采样一般采用人工合成数据策略,其中典型的代表为SMOTE (Synthetic Minority Oversampling Technique) 即合成少数类过采样技术,其基本思想是:对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中
设训练集的一个少数类的样本数为 T ,那么SMOTE算法将为这个少数类合成 NT 个新样本。这里要求 N 必须是正整数,如果给定的 N<1 那么算法将“认为”少数类的样本数 T=NT ,并将强制 N=1
考虑该少数类的一个样本 $i$ ,其特征向量为 $x_i,i∈\{1,…,T\}$ :
(1)首先从该少数类的全部 T 个样本中找到样本 $x_i$ 的 k 个近邻(例如用欧氏距离),记为 $x_{i(near)},near∈\{1,…,k\}$ ;
(2)然后从这 k 个近邻中随机选择一个样本 $x_{i(nn)}$ ,再生成一个 0 到 1 之间的随机数 $\zeta_1$,从而合成一个新样本 $x_{i1}$ :
$$x_{i1}=x_i+\zeta_1(x_{i(nn)}-x_i)$$
从上面的公式就可以看出,SMOTE本质上就是插值
将步骤2重复进行 N 次,从而可以合成 N 个新样本:$x_{i,new},new∈\{1,…,N\}$
那么,对全部的 T 个少数类样本进行上述操作,便可为该少数类合成 NT 个新样本
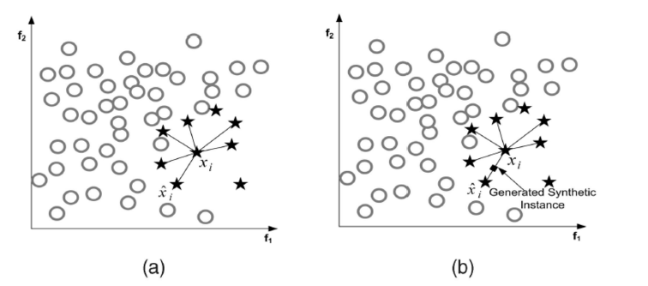
比较上/下采样:
下采样法的时间开销通常远小于上采样法,因为前者丢弃了很多样本,使得分类器的训练集远小于初始训练集,而上采样法则增加了很多样本,使得其训练集大于初始训练集;
*2. Box-Cox变换
Box-Cox变换用来降低X的skewness值,达到接近正态分布的目的
变换公式为:
$$
x’=
\begin{cases}
\frac{x^{\lambda}-1}{\lambda} , & \lambda\neq 0 \\
\log (1+x), & \lambda = 0
\end{cases}
$$
逆变换公式为:
$$
x=
\begin{cases}
(1+\lambda x’)^{1/\lambda} , & \lambda\neq 0 \\
e^{x’}-1, & \lambda = 0
\end{cases}
$$
![]()
上图展示的是$\lambda$取不同值时,x与x’的关系图,Box-Cox变换的工作原理就在这些曲线的斜率中
曲线斜率越大的区域,则对应区域的X变换后将被拉伸,变换后这段区域的方差加大;
曲线斜率越小的区域,对应区域的X变换后将被压缩,变换后这段区域的方差变小;
下面是一个左偏的例子:
![]()
参考资料:
(1) 【干货】Kaggle数据挖掘比赛经验分享,陈成龙博士整理!
(2) 周志华《机器学习》
(3) upsampling(上采样)& downsampled(降采样)
(4) SMOTE: Synthetic Minority Over-sampling Technique,JAIR’2002